마지막 챕터입니다 드디어 딥러닝 교과서 정리가 끝났네요
9.1 생성모델
생성모델은 데이터로부터 확률 분포를 추정해 데이터를 생성하는 모델이다. 실생활 데이터는 매우 복잡한 확률분포를 가지는 만큼 확률분포를 정확하고 빠르게 추정하기 어렵다.
확률분포를 추정하는 모델인만큼 확률기본기념에 대해 짚고 넘어가려한다.
확률의 곱법칙
p(a|b) = p(a∩b)/p(b)
↓유도
p(a∩b) = p(a|b)p(b)=p(b|a)p(a)
결합확률분포는 다음과 같이 두가지 방식으로 나타낼수 있다
확률의 합법칙

표본공간 s에서 a의 발생확률, p(a)를 구한다면 a와 bi의 결합확률분포를 구하고 모든 b에 대해 합산하면 p(a)를 구할 수 있다.이와 같이 일부 확률 변수를 구하기 위해 나머지 확률변수에 대해 합산하는 것을 주변화라고 하며, 이를 확률의 합 법칙이라고 한다.
베이즈 정리
p(A|B) = p(B|A)p(A)/p(B)
A는 가설, B는 증거라고 하면 베이즈 정리는 가설에 대한 믿음을 증거를 토대로 갱신하는 과정을 나타낸다. 가설에 대한 사전 확률 분포 p(A)는 증거를 모르는 상태에서 경험적으로 정의하는 확률분포다. 우도 p(B|A)는 가설이 정해진 상태에서 증거에 대한 확률이다. 정규화상수 p(B)는 증거에 대한 확률분포로 증거와 가설의 결합확률분포를 가설에 대해 주변화한 분포가 된다.p(A|B)는 사후 확률분포로 사후 확률은 증거로 갱신된 '가설 또는 새로운 주장'에 대한 새로운 확률을 말한다.
<판별모델과 생성모델>
판별모델은 관측데이터가 있을 때 각 클래스가 속할 확률을 예측하는 모델이고, 생성모델은 관측데이터의 확률분포를 학습해서 새로운 샘플을 생성하는 모델이다.
판별 모델은 관측 데이터 x가 클래스 Ck에 속할 조건부 확률분포 p(Ck|x)를 예측하는 모델이다. 생성모델을 사용한 분류모델은 사전 확률분포 p(Ck)와 관측데이터의 조건부 확률분포 p(x|Ck)를 구한 뒤 베이즈 정리를 이용해서 사후분포 p(Ck|x)를 예측한다.
p(Ck|x) = p(x|Ck)p(Ck)/p(x)
p(x) = ∑p(x|Ck)p(Ck)
생성모델과 판별모델의 가장 큰 차이점은 생성 모델은 입력 Ck의 확률분포를 가정한다는 것이다. 생성 모델은 관측 데이터의 분포 p(x)를 추론하기 대문에 이상치 탐지와 같이 데이터의 특성을 파악해야 하는 문제에 적용할 수 있다
생성 모델이 잠재변수모델latent variable model인 경우 클래스 Ck를 잠재변수 z로 일반화한다.따라서 잠재변수 생성모델은 z가 주어졌을 때 관측데이터에 대한 조건부확률분포를 p(x|z)로 표현한다
<생성 모델의 종류>
생성모델은 관측 데이터의 확률분포를 추정해서 새로운 샘플을 생성한다. 훈련데이터의 확률분포를 Pdata(x)라고 하면, 생성 모델의 목표는 Pdata(x)를 근사하는 Pmodel(x)을 학습하는 것이다.
생성모델은 관측 데이터의 확률분포를 추정하기위해 최대우도추정을 한다. 최대 우도추정방식은 명시적으로 추정하는 명시적 추정과 모델이 확률 분포를 따르는 샘플을 추정하는 암묵적 추정 방식으로 나뉜다. 명시적 추정 방식은 '확률 분포를 정확히 추정하는 방식'->자기회귀모델 과 '확률분포를 근사적으로 추정하는 방식'->VAE로 나뉘고 암묵적 추정방식에는 GAN이 있다.
자기 회귀 모델은 이미 생성된 자신의 데이터를 이용해 나머지 데이터를 생성하는 모델이다.
p(x) = p(x1,...xn) = ∏p(xi|x1,...xn-1)
자기 회귀 방식으로 계산하려면 각 차원의 순서를 정해야 한다. 그리고 확률의 곱 법칙에 따라 모든 차원의 결합 확률분포는 각 차원의 조건부 확률 분포의 곱으로 정의된다. 이런 방식은 모든 xi가 관측변수가 되기 대문에 FVBN(fully visible belif network)이라고 부른다. 자기 회귀 방식은 모델이 단순해 훈련과정도 안정적이고 관측데이터만으로 확률분포를 정확히 추정할 수 있으나 순차적으로 한 차원씩 생성하는 만큼 학습속도가 매우 느리다
VAE variational autoEncoder
변분 오토인코더는 인코더-디코더로 구성된 잠재변수 모델로 확률분포를 변분적으로 근사한다. 인코더는 관측 변수 x를 표현하는 잠재변수 z의 확률 공간을 p(z|x)를 만들기 위해 사후 확률 p(z|x)를 q(z|x)로 근사한다. 디코더는 잠재변수 z가 표현하는 p(x|z)를 추론한다. VAE는 확률분포에 근사하는 방식이라 훈련과정이 안정적이고 빠르다
GAN
생성자generator와 판별자 discriminiator가 적대적 관계에서 훈련하는 모델이다. 생성자는 가짜 데이터를 만들면서 판별자가 진짜라고 속을때까지 학습한다. 판별자는 훈련데이터는 진짜라고 판별하고 생성자가 만든 데이터는 가짜 데이터로 판별하도록 학습한다. 생성자는 판별자를 통해 훈련 데이터의 확률분포를 간접적으로 학습한다

<생성모델을 어디에 사용할 수 있을까?>
1. 새로운 객체 생성 : 새로운 예술작품생성, 이미지 변환, 다양한 복구 작업, 데이터 증강, 개인정보 생성
2. 확률추정: 이상데이터 탐지
3. 표현 학습: 잠재공간에서 데이터 표현 학습
4. 시계열 데이터 생성: 강화학습에서 미래의 상태 및 행동을 시뮬레이션하거나 계획
이미지 데이터 생성 예시
인페이팅inpainting

이미지 일부가 비어있을때 완성된 이미지가 되도록 빈 부분 채워주는 기법
고해상도 이미지로 변환 SR-GAN 예시

저해상독의 그림을 고해상도로 변환
데이터 증강, 3D모델 생성, 이미지 변환 등 예시가 있다.
9.2 VAE
오토인코더와 확률모델로 확장된 오토인코더인 변분 오토인코더VAE에 대해 알아보자
1)오토인코더
표현학습은 데이터를 가장 잘 표현하는 특징을 학습하는 방법이다. 데이터학습할때 입력데이터를 저차원 데이터로 압축하는 인코더 형태의 모델을 통해 학습한다. 표현학습은 '차원축소', '데이터압축'과정으로 볼 수 있다. 또한 비슷한 데이터를 동일한 특징으로 표현하기 때문에 '클러스터링'이라고도 생각할 수 있다. 표현학습에서 중요한 것은 훈련데이터로부터 응용에 필요한 변동성 요인을 특징으로 얼마나 잘 포착하는 것이냐이다.
오토인코더는 자기자신을 잘 복구하는 표현을 학습하는 신경망이다. 고차원 데이터-> 저차원 데이터로 인코딩 하고 저차원 데이터->고차원 인력 데이터로 디코딩하는 항등함수모델이다.

인코더의 출력 계층을 '병목 계층'이라고 하며 손실함수는 l2손실로 정의된 복원 손실 함수로 표현된다. l2 = |x-x^|^2
학습된 오토인코더는 자기 자신을 잘 복원하는 특징을 학습한 '사전학습모델'로 전이학습에 활용할 수 있다. 전이 학습은 사전에 학습된 모델로 파라미터를 초기화해서 적은 데이터셋으로 세부 튜닝을 하는 학습방법이다.
오토인코더로 새로운 데이터를 생성할 수 있을까? 오토인코더는 본래 학습했던 데이터만 복원할 수 있는 모델이라 새로운 데이터를 생성할 순 없다. 하지만 확률모델로 확장하면 새로운데이터를 생성할 수 있고 이를 VAE라고 한다.
2)잠재변수 확률 모델
실생활에서 확보한 관측 데이터의 확률분포를 추정하기란 쉽지않다. 확률 분포 p(x)가 복잡하다면 여러 개의 분포가 혼합된 분포로 추정할 수 있다 예를 들어 가우시안 혼합 분포를 들 수 있다.

가우시안 혼합 분포는 가우시안 컴포넌트 p(x|z)를 혼합 계수 p(z)로 가중합산한 형태로 정의할 수 있다.
p(x) = ∑p(x|z)p(z)=∑p(x,z)
가우시안 혼합 분포 p(x)는 결합 확률분포 p(x,z)를 z에 대해 주변화해서 추정하는 잠재변수 모델임을 알 수 있다. 이를 이용해 VAE를 유도하는 방정식 등 복잡한 과정은 적기 어려워 생략한다.
9.3 GAN
이 모델은 이안 굿펠로우가 제안했고 머신러닝 분야에서 최근 10년간 가장 흥미로운 모델로 평가받고 있다. 이전 학부스터디에서 교수님께서 주신 데이터로 DCGAN을 구현해 본 적 있다. GAN은 생성자와 판별자가 적대적 관계에서 경쟁하며 훈련하는 방식으로 두 플레이어 간에 미니맥스 게임을 하는 과정으로 볼 수 있으며 내시 균형 상태에 도달하면 게임은 끝난다.

생성자는 저차원의 잠재 벡터 Z를 받아 고차원의 샘플을 생성하고 판별자는 훈련데이터를 진짜로 판별하고 생성자가 생성한 샘플을 가짜로 판단하는 이진 분류기이다. 이미지를 생성할때는 콘벌루션 신경망으로 된 생성자와 판별자를 사용한다. 생성자는 이미지를 업샘플링하므로 트랜스포즈 컨볼루션을 사용한다.
minmaxV(D,G) = Ex~pdata(x)[logD(x)]+Ez~pz(z)[log(1-D(G(z))]

^훈련전 초기상태 판별자 최적화 생성자 최적화 평형 상태
DCGAN
DCGAN은 고화질의 이미지를 생성한 최초의 GAN모델이다. 컨볼루션을 사용한 GAN모델로 생성자는 트랜스포즈 컨볼루션으로 업샘플링하며 판별자는 스트라이드 컨볼루션으로 서브샘플링한다. 활성함수는 생성자는 ReLU를 판별자는 리키 ReLU를 사용하며 배치정규화는 Adam 옵티마이저를 사용한다.
WGAN
GAN은 JSD를 최소화하는 방식으로 설계되었다. 하지만 JSD는 Pdata(x)와 Pg(x)의 두 분포가 겹치지 않고 떨어져 있으면 항상 log2가 된다. 반면 WGAN은 와서스테인거리를 측도로 사용해 두 분포가 겹치지 않아도 거리를 측정할 수 있다. 이는 거리 측도를 바꿈으로써 획기적인 고화질의 이미지를 생성한다.
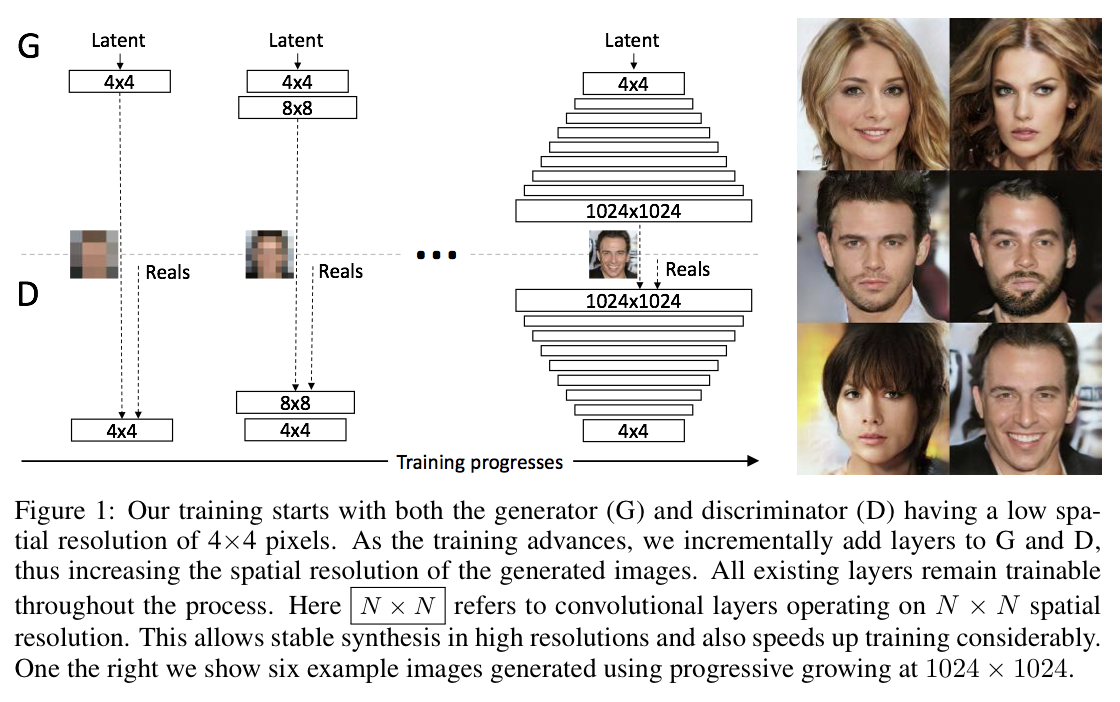
PGGAN
PGGAN은 1024X1024 고해상도 이미지를 생성하기 위해 4X4 저해상도 이미지부터 1024X1024 고해상도 이미지까지 해상도를 높여가며 커리큘럼을 학습하는 GAN모델이다. 해상도가 높아질때마다 생성자는 출력계층이 한 계층 늘어나고 판별자는 입력계층이 한 계층 늘어난다.
Pix2Pix
이미지 변환 기법으로 이미지를 다른 이미지로 변환하는 모델이다. CGAN모델을 사용하는데 CGAN은 데이터의 카테고리에 나타내는 조건을 입력하면 해당 카테고리의 샘플을 생성하는 GAN모델이다. Pix2Pix는 GAN을 확장하여 생성자에 오토인코더나 스킵연결이 있는 U-Net을 사용한다. 그리고 입력은 잠재변수가 아닌 이미지가 된다.

'Deep learning' 카테고리의 다른 글
| CNN의 다양한 모델들 정리 (0) | 2023.10.31 |
|---|---|
| CNN Model에 관하여 (0) | 2023.10.31 |
| Do it! chapter 8: 순환신경망 (0) | 2022.05.18 |
| Do it!딥러닝 교과서 chapter 7 : 컨볼루션 신경망 모델 (0) | 2022.05.17 |
| Do it!딥러닝 교과서 chapter 6. 콘벌루션 신경망 (0) | 2022.05.11 |